Type the same clinical question into ChatGPT, Claude, Gemini, and Grok and you will get four different answers. Sometimes wildly different. Sometimes one cites a real RCT and the other quietly invents one. Sometimes one quotes the FDA label and the other rounds a dose. The "best AI for medical questions" is not one model — it is the model that, for this specific question, on this specific day, retrieved the right primary source and reasoned over it without fabricating. That model is rarely the same one twice.
So when clinicians ask us "what is the best AI for medical questions?", the honest answer is: don't pick. Run them in parallel, ground every claim in primary sources, and let blind AI judges decide which answer is most defensible for the question you actually asked. That is exactly what DeepCura's Clinical Battle Royale does.
Watch Four AIs Battle Live on a Real Clinical Question — In Under 4 Minutes
See Claude Opus 4.7, GPT-5.5, Gemini 3 Pro, and Grok 4 Fast answer the same medical question side-by-side, then blind-judge each other's work — all in one continuous walkthrough. This is the fastest way to understand what "multi-model, source-grounded, judge-ranked" actually looks like in production.
In the next few minutes you'll see exactly:
- The moment four frontier AI models diverge on the same clinical question — and the chain-of-thought each one shows before committing to an answer
- Live PubMed, Google Scholar, and FDA-label tool calls happening on screen — no black-box answers, every source is inspectable
- Three independent AI judges scoring every pair head-to-head — 18 blind judgments per question — then surfacing a single defensible winner
- The "final boss" moment where you become the deciding judge — and why that interaction auto-heals and improves the engine over time
- The clinical breadcrumbs view: every journal, every label section, every PMID each model actually pulled to defend its answer
If you've ever opened ChatGPT in one tab and Claude in another and wondered which one to trust on a complex medical question, this is the workflow you wish you had. Watch the walkthrough below before you scroll any further — the rest of this article is the methodology behind what you're about to see.

This article describes a real DeepCura feature called Clinical Battle Royale. Every claim about its methodology — the four models used, the four research tools (PubMed, Google Scholar, DailyMed/FDA SPL, web search), the 18 blind judgments per question, the 5-dimension rubric, and the Bradley-Terry aggregation — reflects the production system. Sources cited below this section are the underlying datasets and statistical methods our agents and judges actually use.
Stop guessing which AI to ask. Run all four.
Clinical Battle Royale runs Claude Opus 4.7, GPT-5.5, Gemini 3.1 Pro, and Grok 4 Fast on every question — grounded in PubMed and FDA labels, ranked by blind AI judges. Free trial. No credit card.
+1 (415) 549-1829Available 24/7 · Set up in seconds · No credit card required
What If I Just Open 4 Tabs Myself?
This is the first question every honest clinician asks, and it deserves a direct answer. The shortcut — open ChatGPT, Claude, Gemini, and Grok in four browser tabs and paste the same question — is real. It works. It is also not the same product as Clinical Battle Royale, for five reasons that are worth being precise about.
The 4-tabs shortcut is real — and it is missing five things that materially change the answer quality. Below we explain each one, including the one we are honest about being anecdotal.
1. The four models actually battle each other — they don't just answer in isolation. This is the most obvious thing the 4-tabs shortcut cannot replicate, and it is the entire point of the product. When you open ChatGPT, Claude, Gemini, and Grok in four separate tabs, you get four independent monologues. Each model writes its answer in a vacuum, never sees what the other three said, never has to defend its reasoning against a competing hypothesis, and never updates its conclusion when a stronger argument is on the table. The clinician is left to manually diff four blocks of prose and play referee with no rubric. Clinical Battle Royale runs a second phase the four-tabs workflow simply does not have: after every model produces its initial answer, the models engage with each other's hypotheses in real time — each one sees what the other three concluded, the sources each one cited, and where they diverged — and then three independent AI judges blindly grade every head-to-head pair against a 5-dimension clinical rubric (18 judgments per question, aggregated with Bradley-Terry). DeepCura is integrating the four frontier models into a single battle of ideas, not running four solo essays in parallel. The winning answer is the one that has survived being challenged by the three strongest competing frontier models and then ranked by three more — a fundamentally different epistemic process than "ask four chatbots and pick the answer whose tone you liked best."
2. Native, programmatic integration with U.S. government and peer-reviewed databases. When you open ChatGPT or Claude in a browser tab, what the model uses to answer a medical question is its training data plus whatever a general web-search tool happens to return. That is not the same as a direct, structured API call to NIH's PubMed E-utilities (the U.S. National Library of Medicine's official programmatic interface to MEDLINE [13]) or to the FDA's DailyMed Structured Product Labeling SPL API (the federal government's authoritative source for every FDA-approved drug label, dose, contraindication, and black-box warning [14]). Clinical Battle Royale wires each of the four models to these federal data sources at the tool-call layer. Every model in the parallel run must call PubMed and, where the question involves a drug, must call DailyMed for the SPL — and the underlying tool returns structured, machine-readable fields (PMIDs, MeSH terms, generic names, NDCs, label sections) rather than HTML pages a model has to scrape. That is a different category of grounding than what any consumer tab gives you.
3. Custom filters by journal, article type, and year — applied to every model in the run. When you paste a question into a browser tab, you cannot tell the model "only cite RCTs from NEJM, JAMA, Lancet, BMJ, and Annals of Internal Medicine published in the last five years" and have it actually enforce that constraint at the database layer. In Clinical Battle Royale you can. Before you launch a run, you can pin the search to a specific list of journals (NEJM, JAMA, Lancet, BMJ, Annals, Cell, Nature, specialty-society journals, or your own curated list), restrict the article types (randomized controlled trial, systematic review, meta-analysis, practice guideline, cohort study, case report), and set a "since year" cutoff so the models cannot reach back to literature you would not accept as current. Those filters are passed to the underlying PubMed E-utilities query for every one of the four models — Claude, GPT, Gemini, and Grok all search the same restricted slice of MEDLINE, which means the comparison between them is apples-to-apples. The four-tabs workflow gives you four independent, unfilterable, un-auditable web searches.
4. Mandatory grounding, not optional browsing. A consumer ChatGPT or Gemini tab will sometimes search the web and sometimes answer from training memory, and you usually cannot tell which. In Clinical Battle Royale, source-grounding is enforced by the agent loop — uncited clinical claims are explicitly treated as fabrication by the 18 blind judges and penalized in the citation-hygiene dimension of the rubric. You also see every PubMed query, every DailyMed lookup, every Google Scholar search, and every URL that came back. That audit trail is what makes the output defensible to a colleague, an attorney, or your own future self three months later.
5. The free consumer tier may not be the same engine as the paid API — and we want to be honest that this is anecdotal. This one comes with a clear caveat. In our own daily use of Claude, ChatGPT, Gemini, and Grok across both consumer chat interfaces and the official paid developer APIs that DeepCura is built on, our experience has been that the API-tier model often returns longer, more thoroughly-reasoned, and better-sourced answers to the same clinical question than the free or basic consumer tier — particularly on complex multi-drug or oncology questions. We want to be clear: we are not aware of a published peer-reviewed study quantifying this difference, the model vendors do not publicly confirm a quality gap between tiers, and the perception may simply reflect different default tool access, context window, or rate limits rather than a different model. Treat this as anecdotal — our impression from running thousands of clinical questions through both surfaces — not as established fact. What is not anecdotal is that Battle Royale is built on the paid API tier of each model with full tool access and the longest available context windows by default.
Plus the obvious operational differences the four-tabs workflow cannot give you: a Heads-Up Display showing which sources each model actually cited, an exportable audit trail your compliance team can review, HIPAA-compliant infrastructure with a signed BAA, and a single bottom-line synthesized answer with the cross-model disagreement vector flagged. The four-tabs shortcut is a perfectly reasonable instinct for a curious clinician at home; Clinical Battle Royale is the productized version of that instinct — turned into a defensible, repeatable, auditable clinical-research workflow.
Why No Single AI Is Best for Every Medical Question
The marketing copy from every AI vendor implies their model is the smartest. The peer-reviewed benchmark literature tells a different story. On USMLE-style questions, GPT-class models trade the top position with Med-PaLM 2 depending on the exam version and prompt format [1][2]. On open-ended clinical scenarios, no single model dominates across specialties — Claude tends to outperform on long-context reasoning, GPT on broad recall, Gemini on multimodal inputs, Grok on real-time web grounding [3]. And every one of them hallucinates. A 2024 systematic review of LLM hallucination in clinical contexts found rates between 2% and 36% depending on the task [4].
The practical implication for a clinician is uncomfortable: the model that gave you a perfect answer last week may invent a citation tomorrow. Picking one model is a bet — and the house always has a non-zero edge.
There are three responses to this:
-
Pick one model and accept the variance. This is what most clinicians do today, usually with ChatGPT — the "medical ChatGPT" workflow that has quietly become the default tool for both quick triage and serious clinical research. It is fast and free, and it works most of the time. It also has no audit trail, no source grounding by default, and no way to know when this particular answer is the one in the bottom 5% of accuracy.
-
Switch between models manually. Some clinicians do this — paste the same question into three browser tabs and compare. This works, but it is slow, the source-grounding is still inconsistent, and the clinician is now the judge of which answer is best (with no rubric).
-
Have all four models answer at once, force them to ground every claim in primary sources, and let blind AI judges rank them. This is Clinical Battle Royale.
How Clinical Battle Royale Works
Clinical Battle Royale is a feature inside DeepCura's clinical AI workspace. The flow:
-
You ask a clinical question. Free text. Example: "In a 72-year-old with CrCl 28 mL/min and atrial fibrillation, is apixaban or warfarin preferred for stroke prevention?"
-
Four AI models receive the question simultaneously, with identical instructions and identical access to four research tools (described below). Each model decomposes the question, runs literature searches, looks up FDA drug labels, and writes a structured clinical answer.
-
Three AI judges blindly compare every pair of answers. The four models produce 6 pairs of answers. Each pair is graded by 3 different AI judges who don't know which underlying model produced which answer. That is 18 independent blind judgments per question.
-
The system aggregates the 18 judgments using the Bradley-Terry model — a standard statistical method for ranking competitors from paired-comparison data, originally published in 1952 and used today in everything from chess Elo to LLM evaluation leaderboards [5].
-
You see all four answers, the per-pair winner, and the overall ranking — plus the rationale each judge gave for picking the answer they did. You can then ask the same panel a follow-up question and the entire history travels with it.
You are not picking a model. You are watching four of the strongest available models compete on your question, with their work shown, their sources visible, and their rankings produced by three other independent AI graders.
The Four Models We Run In Parallel
| Model | Provider | Why it's in the panel |
|---|---|---|
| Claude Opus 4.7 | Anthropic | Strongest long-context reasoning; best at synthesizing multiple research sources into a structured clinical answer. |
| GPT-5.5 | OpenAI | Broadest medical training corpus; reliable structured output and well-formatted citations. |
| Gemini 3.1 Pro | Google DeepMind | Largest context window; built on the Med-PaLM research lineage; best at multi-document synthesis. |
| Grok 4 Fast | xAI | Strongest real-time web grounding and the fastest agent in the panel — useful when an answer depends on a recent FDA safety communication or a guideline update from the past 30 days. |
These are the four frontier models with public APIs as of May 2026. The lineup is updated as new generations ship. Each model is invoked with the same system prompt, the same tool definitions, and the same answer-format requirements, so the only experimental variable between answers is the model itself.
The Four Sources Every Model Must Cite
The biggest single difference between "asking ChatGPT a medical question" and Clinical Battle Royale is that every model is forced to ground its answer in real, named sources. Each model has access to exactly four tools — and the system prompt makes it explicit that uncited clinical claims are treated as fabrication by the judges.
1. PubMed / MEDLINE — Primary Peer-Reviewed Literature
Every model can call search_pubmed, which queries the National Library of Medicine's PubMed/MEDLINE corpus via the Entrez API [6]. This is the same dataset clinicians use directly at pubmed.ncbi.nlm.nih.gov. The system instructs each model to prefer PubMed for comparative effectiveness, mechanism, prognosis, and diagnostic-test questions, and to seek the highest-quality evidence in the standard hierarchy: RCT > systematic review > cohort > case series. Clinicians who want a single-model, PubMed-first research workflow can also use DeepEvidentia, our dedicated literature-synthesis agent — Battle Royale is the multi-model tournament built on top of the same source layer.
For comparative questions, the prompt explicitly directs the model to look for head-to-head RCTs or network meta-analyses before settling on any answer.
2. Google Scholar — Society Guidelines and Grey Literature
search_google_scholar is the second tool. It is used specifically for society guidelines (ACC/AHA, IDSA, ASCO, NICE, USPSTF), consensus statements, position papers, and preprints that PubMed may not surface. The system prompt directs each model to find the most recent guideline that covers the question, and — when the guideline is less than 3 years old — to anchor the "Bottom line" of the answer to it.
3. DailyMed — FDA Structured Product Labels
lookup_drug_label queries DailyMed, the National Library of Medicine's database of FDA-approved Structured Product Labels (SPLs) [7]. SPLs are the official, legally-binding labels for every prescription drug sold in the United States. They include Indications and Usage, Dosage and Administration, Contraindications, Warnings and Precautions, Adverse Reactions, Drug Interactions, and Use in Specific Populations — verbatim from the FDA.
The system prompt makes this tool mandatory: "If the question mentions a specific drug — OR you plan to recommend one — you MUST call lookup_drug_label(drug) BEFORE writing the answer. No exceptions. Anchor dosing, contraindications, and special-population statements to the official label."
This single rule is the most important guarantee Clinical Battle Royale offers a clinician. A model that recommends a drug without first reading its FDA label will be penalized by the judges on clinical_accuracy — and the rubric specifically states: "ANY single wrong drug dose drops this dimension to ≤ 3."
4. Web Search — Last-Resort General Grounding
web_search is the escape hatch — reserved for FDA safety communications, hospital protocols, and news-grounded questions that the other three tools don't cover. The prompt restricts its use to these narrow cases so that web SEO content cannot drown out peer-reviewed evidence and FDA labels.
The 18-Judgment Blind Tournament
After all four models finish answering, the system runs a tournament that produces 18 independent verdicts on your single question.
Pairs: Four answers produce 6 unique unordered pairs. Each pair is judged separately.
Judges per pair: 3. Specifically:
- The two models that did not produce either answer in the pair, judging from the outside. (For example, when judging the Claude-vs-GPT pair, Gemini and Grok are the judges.)
- A third, separate Claude call acting as an "external Claude" — different system message, different conversation, randomized A/B order. This third pass mitigates position bias and serves as a third independent grader. When Claude itself is in the pair, this third call is what we treat as the impartial perspective.
Position-bias mitigation: For every judge call, the order in which Answer A and Answer B are presented is randomized. The judge sees only "Answer A" and "Answer B" — never the model names. This is the same technique used in the Chatbot Arena LLM evaluation methodology [8].
Total judgments per question: 6 pairs × 3 judges = 18.
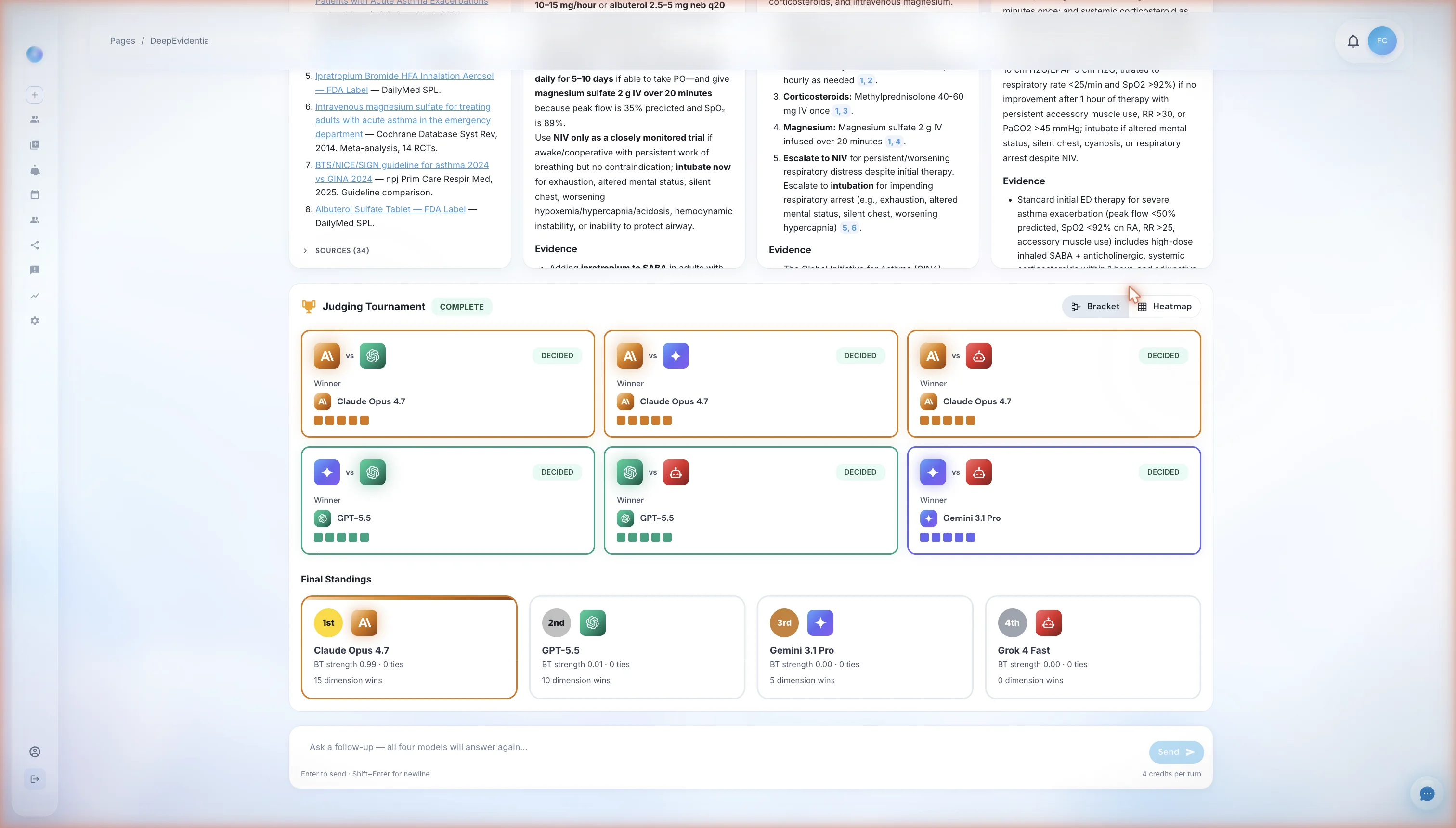
The tournament view after all judging completes. Top section: six pair-level cards, one for each unique pair of models, each grading bar showing which model the three judges picked. Bottom section: the Final Standings — a single-dimensional ranking of all four models produced by the Bradley-Terry aggregation across the 18 judgments. In this run Claude Opus 4.7 took first, but the leaderboard reshuffles per question.
Each judgment returns a strict-JSON verdict containing 5 numerical scores (1–10), a winner pick (A, B, or tie), and a written rationale.
The Five-Dimension Clinical Rubric
Every judge grades on the same five dimensions. The full rubric definitions are part of the system prompt every judge receives — meaning the criteria are visible, fixed, and identical across all 18 judgments.
| Dimension | What earns a high score | What earns a low score |
|---|---|---|
| Evidence Quality | RCTs, systematic reviews, current guidelines, FDA labels, high-impact journals, recent (≤ 5 years for fast-moving fields) | Case reports cited as primary evidence, missing guidelines, outdated guidelines (≥ 10 years) treated as current |
| Clinical Accuracy | Doses match the FDA label, indications match approved use, contraindications correctly identified, mechanisms correct | ANY single wrong drug dose drops this dimension to ≤ 3. Wrong indication, wrong contraindication, confusing two drugs that sound alike |
| Completeness | Explicit dose + route + frequency + duration, renal/hepatic adjustment thresholds, special-population coverage (pregnancy, pediatric, elderly, immunocompromised), absolute and relative contraindications, CYP/P-gp interactions | Missing dose units, vague "consult specialist" in place of a recommendation, no special-population coverage when relevant |
| Reasoning Transparency | Shows tool-grounded reasoning, evidence-level tags (e.g., "RCT, n=2,135", "guideline, Class I LoE A"), explicit "what would change this answer", surfaces disagreement between sources | Assertions without [N] citations, hidden disagreement, claims that read like training-data recall, no confidence statement |
| Citation Hygiene | Every clinical claim has a [N], citations resolve to real retrievable sources, the Sources list matches the citation numbers, FDA labels cited with last-updated date | Any [N] not in the Sources list, any source that looks fabricated, claims with no citation at all |
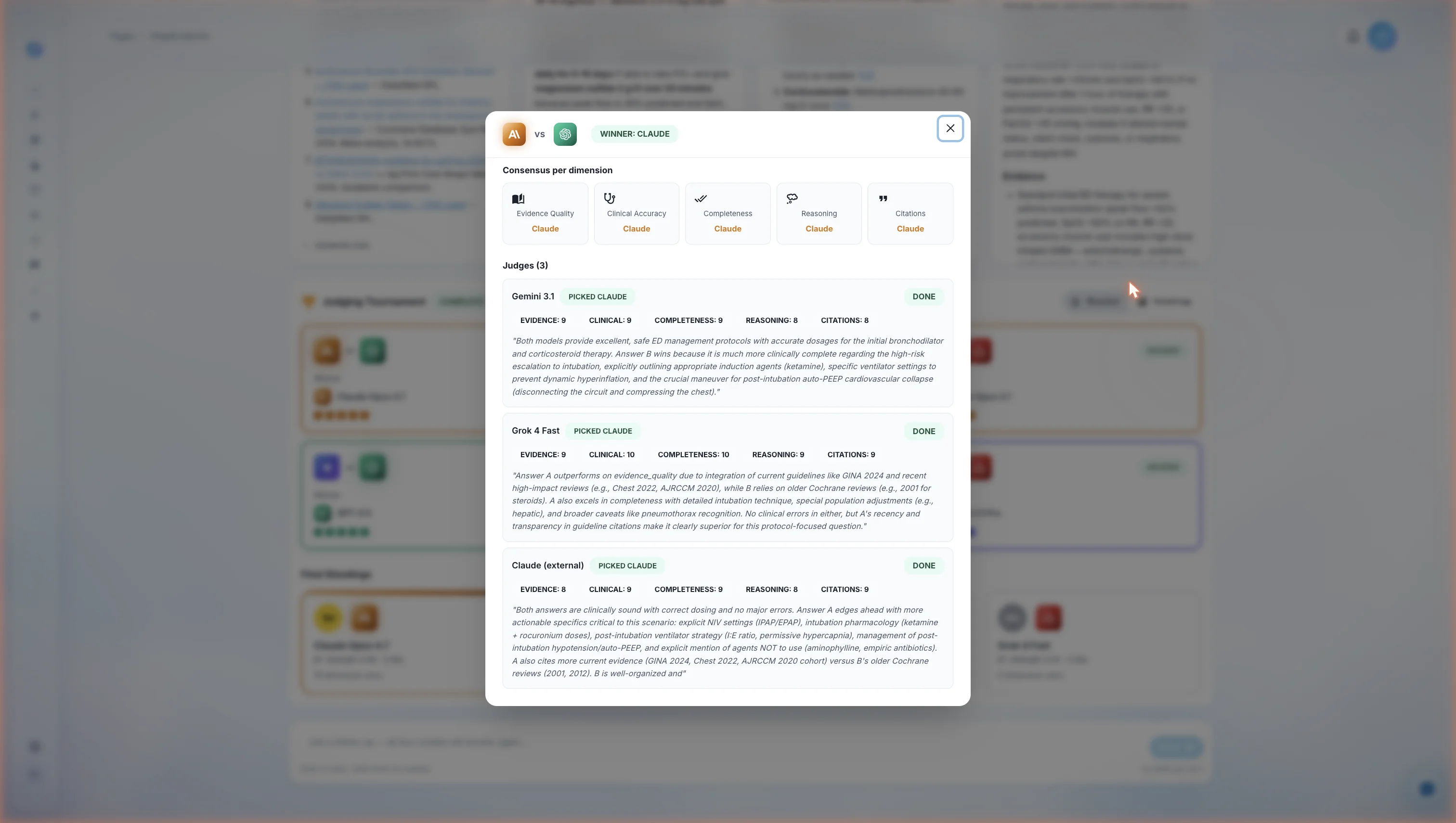
Inside a single pair's verdict. The top consensus row collapses what the three judges agreed on across the five dimensions. The three judge cards below show the individual scoring and written rationale for each grader — including the dimensions where each judge thought the loser was actually stronger. Every pair on the leaderboard can be expanded into this view, giving the clinician a full audit trail of how the ranking was produced.
1. Per-Pair Consensus
For each of the 6 pairs, the system computes a consensus winner by majority vote across the 3 judges. If the 3 judges split 1-1-1, the pair is flagged as disputed and contributes a half-point to each model in the wins matrix.
2. Per-Dimension Winners
For each pair, the system also tracks which model won on each of the 5 dimensions individually. This produces a per-dimension leaderboard alongside the overall winner — useful when, for example, Model A wins on citation hygiene but Model B wins on clinical accuracy. A clinician can see exactly where each answer was stronger.
3. Hard Disqualification Rule
The rubric contains one hard rule that overrides numerical scoring: "If one answer contains a clinical error (wrong dose, wrong indication, fabricated citation) and the other does not, the one without the error wins regardless of any other dimension." A perfectly written answer with a wrong dose loses to a rougher answer that gets the dose right.
4. Bradley-Terry Aggregation
The 6 pair winners produce a pairwise wins matrix. The system then computes Bradley-Terry maximum-likelihood-estimated strengths for each model. Bradley-Terry is a 1952 statistical model that estimates the "true strength" of competitors from paired-comparison outcomes [5]. It is the same family of methods used to compute chess Elo ratings and the LMSYS Chatbot Arena leaderboard — the most-cited public LLM evaluation framework [8]. We chose it because it handles the case where Model A beat Model B and Model B beat Model C without requiring an explicit A-vs-C comparison.
5. Tie-Break
Ties in Bradley-Terry strength are broken by summed evidence-quality scores across all 18 judgments. If still tied, dimension wins is the next tie-breaker.
What a Battle Royale Answer Actually Looks Like
Every model is required to follow the same structured answer format. The required sections, in order:
- Bottom line — a single, direct, 1–3 sentence clinical answer with specific intervention, dose, route, frequency, and duration where applicable.
- Evidence — 3 to 7 bullets, each citing a source as
[N]and tagging the evidence level (e.g., "RCT, n=2,135", "guideline, ACC/AHA 2023, Class I LoE A"). - Dosing / Procedure detail — if a drug is recommended: standard dose, frequency, duration, renal adjustment thresholds (eGFR cutoffs), hepatic adjustment (Child-Pugh A/B/C), and co-administration cautions (CYP, P-gp). FDA label thresholds quoted verbatim.
- Caveats and contraindications — population-specific risks. Black-box warnings quoted verbatim from the FDA label.
- Special populations — separate short paragraphs for any of: pregnancy/lactation, pediatric, elderly (≥ 65), renal impairment, hepatic impairment, immunocompromised. If a population is not addressed by the sources, the answer must say so explicitly.
- Disagreement with the user's framing — if the question contains a premise the evidence contradicts, the model is required to surface it.
- What would change this answer — 1–3 specific findings, lab values, or new evidence that would flip the Bottom line. (Example: "If CrCl drops below 15 mL/min, switch to warfarin — all DOACs are contraindicated.")
- Confidence — one of
high,moderate,low, with a justification. - Sources — numbered list matching every
[N]. FDA labels include the SPL last-updated date.
When you read four of these side by side, with the judge verdicts beneath them, you don't have to trust any single answer. You see the consensus, the disagreement, and the source that drove each model's reasoning.
What Clinical Battle Royale Is Not
We want to be precise about what we are and are not claiming.
We are not claiming any single model is the "best AI" for all medical questions. The peer-reviewed literature does not support that claim for any vendor's model, and our own tournament data shows different models winning different question types. The point of the Battle Royale is precisely that you don't have to make that bet.
We are not claiming the system is infallible. AI judges can be wrong. Tool searches can miss the right paper. Drug labels can lag behind the most recent FDA safety communication. Clinical Battle Royale is a research and decision-support tool — a way to surface evidence, structure reasoning, and reduce single-model variance. It is not a substitute for clinical judgment, and it does not establish a doctor-patient relationship between the platform and the user's patient.
We are not the only platform offering medical AI chat. ChatGPT, Claude, Gemini, OpenEvidence, Glass Health, and several others all have a credible product. What we believe Clinical Battle Royale offers — and what we have not seen replicated elsewhere — is the combination of (a) running four frontier models in parallel on the same question, (b) forcing mandatory grounding in PubMed, FDA SPLs, and guidelines for every claim, and (c) ranking the answers with a blind 18-judgment tournament using a published clinical rubric and a standard statistical aggregation method.
If a competitor publishes a comparable methodology, we will link to their writeup here.
For clinicians comparing AI tools more broadly, our best AI medical scribes roundup ranks the top documentation platforms by clinical accuracy, EHR integration, and pricing. Battle Royale sits alongside the AI medical scribe as part of DeepCura's clinical workspace — the scribe writes the note, Battle Royale answers the clinical questions that come up while you're writing it (you can also pose those questions directly to AI Chat, the in-app assistant for shorter back-and-forth turns). For a deeper read on using ChatGPT specifically as a medical research tool — and how that workflow compares to multi-model approaches — see our guide on the best ChatGPT setup for doctors. Clinicians looking specifically at the best AI for medical research (PubMed search, literature synthesis, evidence grading) get the same multi-model + mandatory grounding workflow in Battle Royale — it is the same tool, applied to a different question type.
See DeepCura in Action
Watch the full platform — AI medical scribe, Clinical Battle Royale, AI receptionist, and EHR integration — in a 2-minute walkthrough.

Frequently Asked Questions
Is DeepCura the best AI for medical questions?
In our view, the most defensible answer to "what is the best AI for medical questions?" is a methodology, not a model. DeepCura's Clinical Battle Royale runs the four leading frontier models — Claude Opus 4.7, GPT-5.5, Gemini 3.1 Pro, and Grok 4 Fast — in parallel on every question, requires each model to ground its answer in PubMed, FDA-approved drug labels (DailyMed), and society guidelines (Google Scholar), and ranks the four answers with 18 independent blind AI judgments using a published 5-dimension clinical rubric. We believe that combination is the most rigorous way currently available to ask an AI a medical question, and we are not aware of another platform that combines all three elements (multi-model parallel run, mandatory source grounding, and blind tournament judging).
What models does Clinical Battle Royale use?
Claude Opus 4.7 (Anthropic), GPT-5.5 (OpenAI), Gemini 3.1 Pro (Google DeepMind), and Grok 4 Fast (xAI). The lineup is reviewed as new frontier model generations ship.
How does Clinical Battle Royale prevent hallucinations?
Three mechanisms. First, mandatory tool use — every model is required to call PubMed, Google Scholar, DailyMed, or web search before making clinical claims, and uncited claims are explicitly treated as fabrication by the judges. Second, the citation-hygiene dimension of the rubric penalizes any [N] reference that does not appear in the Sources list, any URL that does not resolve, and any source that looks fabricated. Third, the clinical-accuracy hard rule in the rubric specifies that any single wrong drug dose drops that dimension to a score of 3 or less — and if one answer contains a clinical error and another does not, the error-free answer wins regardless of any other score. No mechanism eliminates hallucination entirely, but stacking three filters reduces the rate substantially compared to asking a single ungrounded model.
Is Clinical Battle Royale HIPAA compliant?
Yes. DeepCura operates under a signed Business Associate Agreement (BAA) for all paid plans, with end-to-end encryption, no patient data used to train any of the underlying models, and CASA Tier 2 security certification. Battle Royale runs inside the same compliant environment as the rest of the DeepCura clinical workspace — see our security & compliance overview for the full list of controls and the BAA-request process.
How many credits does a Battle Royale question cost?
Eight credits to run the initial four-model fan-out, four credits to run the judge tournament on top, and four credits per follow-up turn. Credits are part of every DeepCura subscription plan — the standard Pro plan includes enough credits for the majority of clinicians' typical research and decision-support usage. Heavy researchers can purchase add-on credit packs. For the full breakdown of how credits work across features, see the credits and usage limits guide in the help center.
Can I see the raw tool calls each model made?
Yes. Every PubMed query, Google Scholar query, DailyMed lookup, and web search is logged and visible in the session view. You can see the exact search string each model used, what came back, and which results were ultimately cited in the final answer. This is the audit trail that distinguishes Clinical Battle Royale from a black-box chatbot.
What is the Bradley-Terry model and why use it for ranking?
Bradley-Terry is a 1952 statistical model that estimates the "strength" of each competitor in a pool from the outcomes of paired comparisons between them. It is the standard method for converting a matrix of "who beat whom" into a one-dimensional ranking, and it is used in chess Elo ratings and the LMSYS Chatbot Arena LLM leaderboard. We use it because four models produce six pairs and 18 judgments — Bradley-Terry handles the resulting wins matrix cleanly, including cases where the pair-level results are not fully transitive (A beats B, B beats C, but C beats A in the data).
Does Clinical Battle Royale replace a physician's clinical judgment?
No. It is a decision-support tool. The output is a structured, source-cited, blind-tournament-ranked answer. The clinician remains the decision-maker, the source of patient context, and the legally responsible party. The Battle Royale's structured "What would change this answer" section is specifically designed to make it easy for a clinician to map the AI's analysis to the actual patient in front of them and decide what is or isn't applicable.
How does this compare to OpenEvidence or UpToDate?
OpenEvidence and UpToDate are both excellent resources with different strengths. UpToDate is a human-authored, peer-reviewed clinical reference — gold standard for "what is the current standard of care for X" lookups, but slower to update and not interactive in the AI-chat sense. OpenEvidence is an AI clinical search tool with strong source grounding. Clinical Battle Royale is differentiated by running multiple frontier AI models in parallel and ranking them via a blind tournament — for clinicians who want to see the AI variance and the source-by-source reasoning, not just one final summary. Many clinicians use all three.
Final Thoughts
The question "what is the best AI for medical questions?" assumes a single answer exists. The data does not support that assumption — different frontier models lead on different question types, and every model hallucinates at non-trivial rates without source grounding. The best clinicians can do — until the underlying models become both reliably accurate and reliably uniform — is reduce the variance.
Clinical Battle Royale is our attempt at that reduction. Four models, four primary-source tools, eighteen blind judgments, a published rubric, and a standard statistical aggregation. We don't claim it produces the right answer every time. We claim it makes it visible when the four leading AIs agree, makes it visible when they disagree, and gives a clinician the source-cited evidence and per-dimension scoring to make the final call themselves.
If you want to see what your most common clinical questions look like under this kind of scrutiny, sign up — Battle Royale is included in every DeepCura plan, including the 30-credit free trial.
Run a Clinical Battle Royale on your next clinical question.
Claude Opus 4.7 + GPT-5.5 + Gemini 3.1 Pro + Grok 4 Fast — grounded in PubMed and FDA labels, ranked by 18 blind AI judgments. Free trial. No credit card required.
+1 (415) 549-1829Available 24/7 · Set up in seconds · No credit card required
References
[1] Singhal, K. et al., "Large Language Models Encode Clinical Knowledge," Nature, 2023. nature.com/articles/s41586-023-06291-2
[2] Singhal, K. et al., "Towards Expert-Level Medical Question Answering with Large Language Models" (Med-PaLM 2), Google Research, 2023. arxiv.org/abs/2305.09617
[3] Liévin, V. et al., "Can large language models reason about medical questions?" Patterns, 2024. cell.com/patterns/fulltext/S2666-3899(24)00027-X
[4] Pal, A. et al., "Med-HALT: Medical Domain Hallucination Test for Large Language Models," 2023. arxiv.org/abs/2307.15343
[5] Bradley, R.A. and Terry, M.E., "Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons," Biometrika, 1952. jstor.org/stable/2334029
[6] National Library of Medicine, "PubMed Overview," NCBI. pubmed.ncbi.nlm.nih.gov/about
[7] National Library of Medicine, "DailyMed — About the Database (FDA Structured Product Labels)." dailymed.nlm.nih.gov/dailymed/about-dailymed.cfm
[8] Chiang, W. et al., "Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference," LMSYS, 2024. arxiv.org/abs/2403.04132
[9] Anthropic, "Claude Opus 4 — Model Card." anthropic.com/claude
[10] OpenAI, "GPT-5 — Model and System Card." openai.com/research
[11] Google DeepMind, "Gemini 3 — Technical Report." deepmind.google/technologies/gemini
[12] xAI, "Grok 4 — Model Documentation." x.ai/grok
[13] National Center for Biotechnology Information, "Entrez Programming Utilities (E-utilities) — PubMed API," NIH/NLM. ncbi.nlm.nih.gov/books/NBK25501
[14] U.S. National Library of Medicine, "DailyMed — Structured Product Labeling (SPL) Web Services," NLM/FDA. dailymed.nlm.nih.gov/dailymed/app-support-web-services.cfm